Project Details
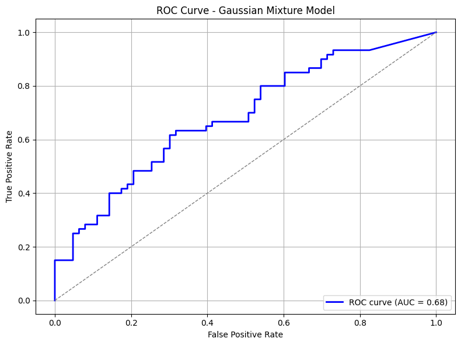
In my Intro to Data Science class I got the opportunity to do a machine learning project in a small group. I worked with two classmates and we were allowed to use a data set of our choosing, so I suggested a data set I had been working on.
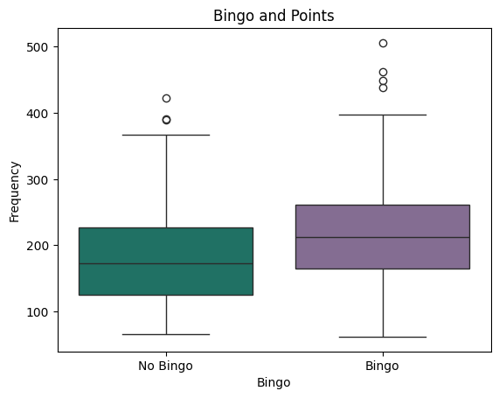
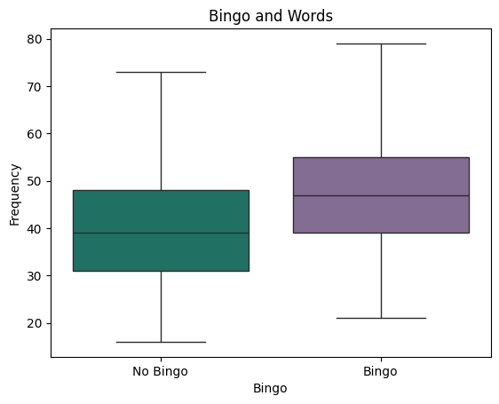
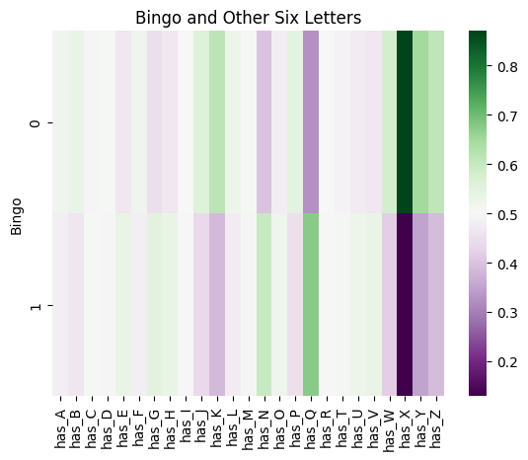
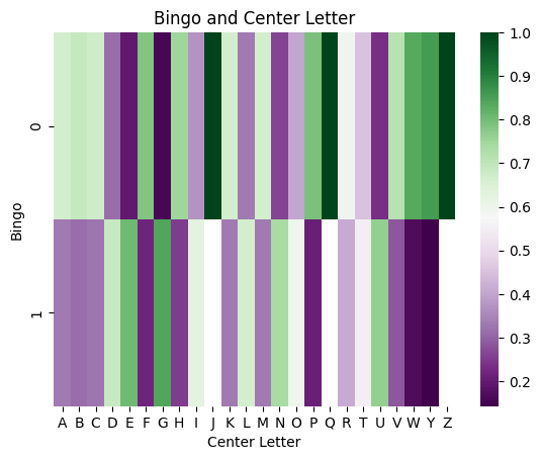
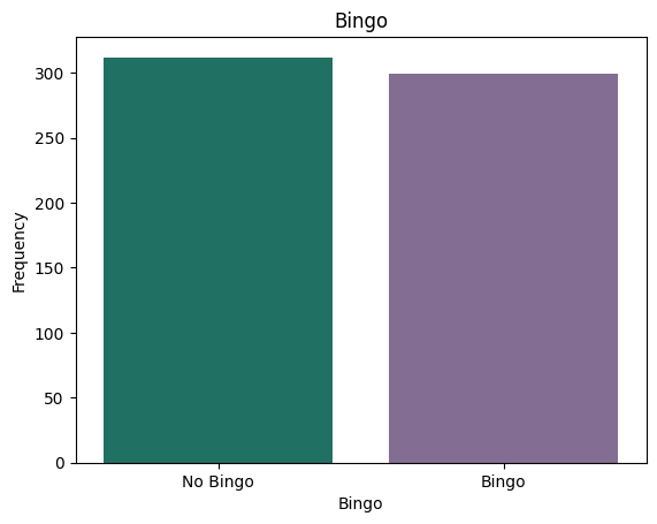
Since August 1, 2023 I have recorded the letters and "hint line" in each day's New York Times Spelling Bee puzzle. At the time we worked on this project, I had just over 600. We focused on only one aspect of the puzzle out of the many ideas I have to explore the dataset when I finish my official data collection on July 30, 2027.
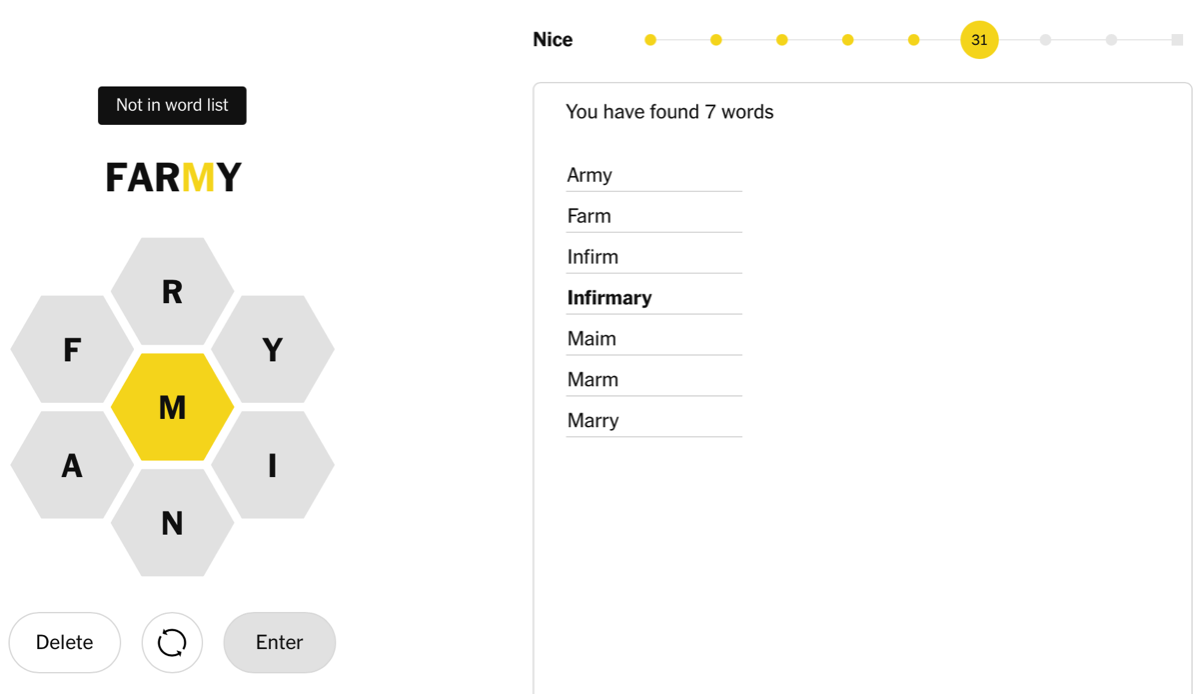
Spelling Bee game in progress